Unicode支持超过一百万种字符;
每个字符分配一个编号,成为编码点;在Python中,编码点写作\uXXXX的形式,其中XXXX是四位十六进制数;
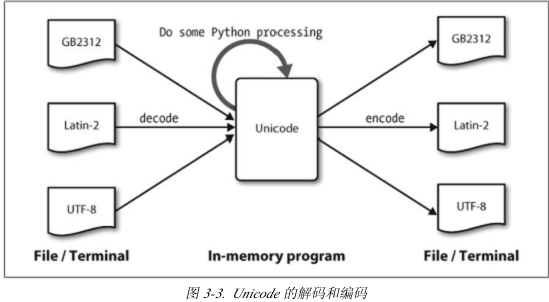
从文件中提取已编码文本
#得到一个文件的路径(知道这个文件的编码)path= nltk.data.find('corpora/unicode_samples/polish-lat2.txt')import codecsf=codecs.open(path,encoding=’latin2’)#从文件对象f读出的文本将以Unicode返回,如果想在终端查看,必须使用合适的编码对它进行编码;unicode_escape是一种虚拟的编码for line in f:line=line.strip()print line.encode(‘unicode_escape’)Python中pring语句假设Unicode字符的默认编码是ASCII码nacute=u’\u0144’nacute_utf=nacute.encode(‘utf8’)print repr(nacute_utf)
在Python中使用本地编码
在文件的第一行或者第二行中包含字符串
# -*- coding:utr-8 -*-